
It’s been a year since I first wrote on the topic of artificial intelligence (AI) and machine learning methods and their application to our field of sports science. But a year feels like a century in the field of data science today. Just consider the pace at which new algorithms and papers are being published daily. Whereas there is no prize more important for a sport scientist pursuing a career in academia than publishing one’s work in a quality journal, for a data science researcher, publishing within conference proceedings are the main goal (see for example at CVPR). Here, pre-prints are the more common currency in data science, as manuscripts are updated continually, creating different versions of the same work on a monthly basis.
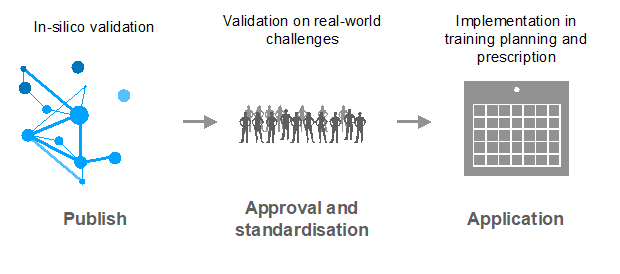
Datasets are often made open so that other researchers can test and develop new algorithms using the same numbers. In contrast, sport scientists are often reluctant to implement new methodologies in their daily practice, requiring testing across multiple studies, with results published and validated in peer-reviewed journals prior to implementation in the real world (Figure 1). So while data science model developers often feel hindered by the slow innovation pace of sport scientists, sport scientists can equally feel both disoriented and sceptical by the pace of technological innovations.
 I began engaging with data scientists a few years ago, and I felt this same disorientation. I got the fear that something I had worked so hard on, could suddenly slip away. I thought I had made the mistake of not getting interested in AI early enough, like when I was in high school. In doing so, I could have had more work opportunities, alongside more chances to ride the AI-wave and publish more papers. Suddenly, I felt that AI was stealing my chance to grow as a scientist. Indeed, I had already devoted much of my research career to the development of equation-based mathematical models. So now I suddenly felt useless in a way. The world no longer needed my mathematical models. The machines were taking over to explain the world to me. No longer any need to conceptualise. No need to mathematically formulate the laws of physics anymore. The greatest show on earth was slowly fading.
Of course, time keeps rolling along, and I started realising that the hype of AI was probably exceeding the actual state of what was both scientifically valid and what was actually implementable within sports science. I started embracing the new technologies without the fear of losing my position, and I started using new AI tools, just as a kid plays with a new toy, or a musician plays with a new guitar. In my first blog post, I made the analogy between new AI tools and classic vs electric guitars (apparently, some got the analogy, but some did not). I think that in this regard, the process of coaching is no exception. I described the acute physiological response to training, and the rationale for implementing AI algorithms (7) to predict oxygen uptake (VO2) values from cycling power output (8), as well as showing how ventilatory threshold prediction can be improved with AI methods within cardiopulmonary exercise testing (9).
In this post, I would like us to consider how these methods might assist us to monitor and optimize the chronic physiological adaptations that occur with training, as well as how AI models might be used subsequently to develop more data-driven and systematic approaches to training program design.
In fact, if we ask ourselves: wouldn’t it be great to have a machine-based coach? One that we trusted? One that uses AI that could guide us in our training sessions day-by-day until our next performance? One that automatically adjusted the training irrespective of what actually occurred in any given training session? Besides the ethics-based issue that considers athletes using such methods to be receiving an unfair advantage (which might be totally irrelevant in our performance-driven world), I will focus here on the more technical questions the reader may have. For example: what do you actually mean when you say “rely on an intelligent coach”? What’s the metric? And at what point would we eventually be able to actually rely less on our human coaches and instead actually trust machine-made decisions?
In an attempt to address these questions, my discussion will be divided into two main sections: independency and intelligence.
Independence (or autonomy) of a machine coach
The Society of Automotive Engineers (SAE) originally described 5 levels of autonomous driving, a roadmap that has been modelled for the application of AI in medical care by E. Topol (6). Following these leads, I’ve attempted to form a similar roadmap for the application of AI to coaching (Figure 2).
I began engaging with data scientists a few years ago, and I felt this same disorientation. I got the fear that something I had worked so hard on, could suddenly slip away. I thought I had made the mistake of not getting interested in AI early enough, like when I was in high school. In doing so, I could have had more work opportunities, alongside more chances to ride the AI-wave and publish more papers. Suddenly, I felt that AI was stealing my chance to grow as a scientist. Indeed, I had already devoted much of my research career to the development of equation-based mathematical models. So now I suddenly felt useless in a way. The world no longer needed my mathematical models. The machines were taking over to explain the world to me. No longer any need to conceptualise. No need to mathematically formulate the laws of physics anymore. The greatest show on earth was slowly fading.
Of course, time keeps rolling along, and I started realising that the hype of AI was probably exceeding the actual state of what was both scientifically valid and what was actually implementable within sports science. I started embracing the new technologies without the fear of losing my position, and I started using new AI tools, just as a kid plays with a new toy, or a musician plays with a new guitar. In my first blog post, I made the analogy between new AI tools and classic vs electric guitars (apparently, some got the analogy, but some did not). I think that in this regard, the process of coaching is no exception. I described the acute physiological response to training, and the rationale for implementing AI algorithms (7) to predict oxygen uptake (VO2) values from cycling power output (8), as well as showing how ventilatory threshold prediction can be improved with AI methods within cardiopulmonary exercise testing (9).
In this post, I would like us to consider how these methods might assist us to monitor and optimize the chronic physiological adaptations that occur with training, as well as how AI models might be used subsequently to develop more data-driven and systematic approaches to training program design.
In fact, if we ask ourselves: wouldn’t it be great to have a machine-based coach? One that we trusted? One that uses AI that could guide us in our training sessions day-by-day until our next performance? One that automatically adjusted the training irrespective of what actually occurred in any given training session? Besides the ethics-based issue that considers athletes using such methods to be receiving an unfair advantage (which might be totally irrelevant in our performance-driven world), I will focus here on the more technical questions the reader may have. For example: what do you actually mean when you say “rely on an intelligent coach”? What’s the metric? And at what point would we eventually be able to actually rely less on our human coaches and instead actually trust machine-made decisions?
In an attempt to address these questions, my discussion will be divided into two main sections: independency and intelligence.
Independence (or autonomy) of a machine coach
The Society of Automotive Engineers (SAE) originally described 5 levels of autonomous driving, a roadmap that has been modelled for the application of AI in medical care by E. Topol (6). Following these leads, I’ve attempted to form a similar roadmap for the application of AI to coaching (Figure 2).
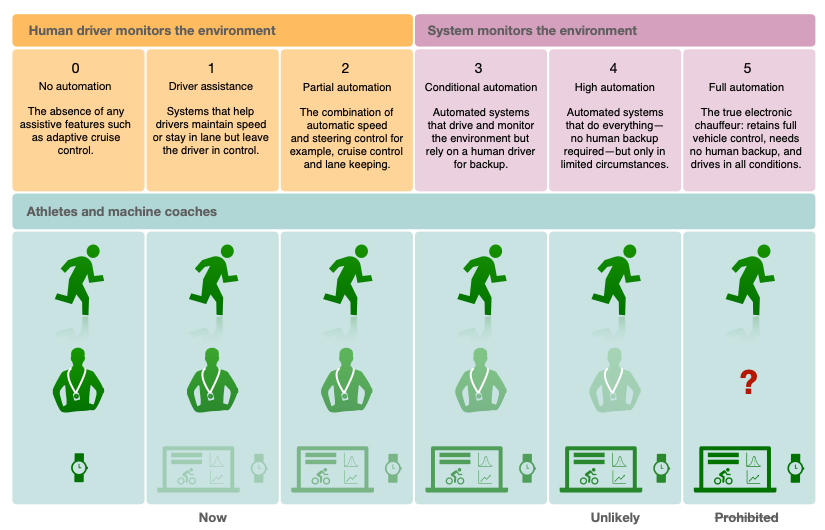 Unfortunately, the comparison is not straightforward: a car (i.e. the artificial intelligent agent) can act directly on the physical system and actively/passively control the trajectory of the car (e.g. lane keeping control) or the velocity (e.g. cruise control). It’s hard to imagine how such active/passive control could be made by an artificially intelligent coach on an athlete. But we can say that from Level 0 to 5, the choice concerning the training load (intensity, duration), recovery periods, pacing strategies, etc., could progressively be made better by such an artificial intelligence compared to the human coach.
At Level 0 in cars, there are no assistive features; instrumentations are only used for a driver’s visual feedback. The same applies in an athlete that uses a GPS device to adjust their running pace, and also for a coach or sport scientist that might be planning training using TRIMP (1) or other measures of training load. Here, we assume there is no contribution from an artificial coach that might process training indexes autonomously and independently (e.g. average session HR).
At Level 1 in athletes/coaches, we might see examples where athletes or coaches begin trusting the data more than their gut feelings. Is this hard to believe? Perhaps this is where the debate surrounding the use of power meters in cycling is at currently (see e.g. Cycling Weekly). More often than not, cyclists may rely on numbers provided by their power meter and HR monitor and adjust the pace accordingly. The main difference between Level 0 and 1 is, in this case, reliance on the artificial system, over trust in personal feelings, knowledge, and intuition i.e.: the human factor.
From Level 2 to 4, there is a progressive overtaking of AI over human intelligence in the decision-making processes. This implies an increasing reliance on sensors, data and software that can automatically compute and prescribe training loads and recovery behaviour autonomously. At these levels, coaches design the training programs alongside their known context, but in accordance with the instructions provided by the machines, prior to delivery to the athlete.
Level 5: end of the relationship between athlete and human coach. The athlete must rely only on the machine coach for every decision. Here, it’s important to note that this level is prohibited by law in the case of autonomous driving, which is why I left a question mark in my example on coaching and sport in general. Sport is highly performance-driven, and if it can be proven that machine coaches are better than human coaches, then athletes and/or performance management will naturally shift to reap the rewards.
The intelligence of a machine coach
My interest in the modelling of the chronic adaptations to training dates back to 2013 when I first read the paper by Clarke and Skiba (4). I’m sure I’m not the only scientist that finds inspiration from their manuscript and their simple implementation of Banister’s dose-response model (1) in an Excel spreadsheet! Forty-five years following its first release, the Banister model is still implemented today, and counts an impressive 332 citations (source: Scholar). In a recent paper published in EJSS, Mitchell et al. (5) compared the performance of the Banister model with an artificially intelligent model (a neural network) in tracking and predicting performance in three elite swimmers. Not surprisingly, the neural network outperformed the other equation-based models in the tracking test, but performance was not maintained in the prediction phase. Correctly, the authors conclude that a model with more parameters is needed to better interpolate the data, but equally might perform worse in predicting the next performance point. Understandably, the authors call for other data sources (such as: propelling efficiency), different from performance and training data alone.
When developing an AI, we should consider that we might want to apply the same algorithm in different tasks. The ability to perform well in different tasks remains the holy grail of the implementation of artificial intelligence in sport science and coaching, as this is one of the most important traits of an intelligent system. On this note, in a recent pre-print paper (3), François Chollet (the father of Keras (2)) proposes a set of guidelines for defining intelligence. This new definition relies on concepts such as the prior knowledge, experience, generalisation difficulty and skill-acquisition efficiency. According to the author, this is only meant to compare different intelligences (e.g. human vs. artificial) and not to challenge only human intelligence. One of the pillars that constitute the structure of this new definition of intelligence is the “efficiency with which a learning system turns experience and priors into skill at previously unknown tasks”.
What does this mean for the machine coach that could progressively take over the human coach from a 0 to 5 level? Let’s assume that we were able to implement the perfect artificial intelligent Banister model. We would first need to confirm that this model is able to predict the performance of athletes across a number of different tasks. In this case, the term generalizability might indicate the ability of the coach to transfer the prior and acquired knowledge to other athletes. A greater ability to generalize might indicate that the coach is able to transfer the knowledge across different populations, e.g., from athletes to sedentary individuals. An even higher level might indicate the ability to predict adaptations to a hot environment, to different diets, to caffeine ingestion, and on and on and on!
It’s really hard for me to picture a future where machines will be able to collect their own notions of physiological adaptations, before connecting them and deploying their own ideas. It’s easier to imagine a future where humans will leverage the computational and storing ability of the machines, and where artificially intelligent systems will be used by humans to think wider and deeper. If you think deeply on the topic, we are already exploiting the ability that machines have to connect notions. We rely on the storage offered by machines to look for definitions, data and numbers (just consider the “collective intelligence” developed within the Wikipedia project). We use machines even to connect thoughts, to make decisions and, at the end of the day, we literally think together with them. With the shortening of the computational times, the growth of cloud computing and cloud storages, I believe that the ability to exploit this hybrid thinking will make the difference in the great majority of our applications.
Conclusion
The thought that I can understand the universe where I am now, how the human body reacts to different exercise stresses and why is absolutely wonderful. The fact that I can leverage human-made AI to go even deeper in my understanding, makes everything even more exciting. In the last decades, data scientists opened a door of wonder for us, and I have no sense whatsoever that they diminished anything. Our need to conceptualise and understand the world surrounding us, will not be diminished, nor demolished, by any AI. To me, this quest to seek the truth, a core endeavour of humanity for researchers and scientists, is still the greatest show on earth.
*Title of this blog post was inspired by the work of Richard Dawkins
REFERENCES
Unfortunately, the comparison is not straightforward: a car (i.e. the artificial intelligent agent) can act directly on the physical system and actively/passively control the trajectory of the car (e.g. lane keeping control) or the velocity (e.g. cruise control). It’s hard to imagine how such active/passive control could be made by an artificially intelligent coach on an athlete. But we can say that from Level 0 to 5, the choice concerning the training load (intensity, duration), recovery periods, pacing strategies, etc., could progressively be made better by such an artificial intelligence compared to the human coach.
At Level 0 in cars, there are no assistive features; instrumentations are only used for a driver’s visual feedback. The same applies in an athlete that uses a GPS device to adjust their running pace, and also for a coach or sport scientist that might be planning training using TRIMP (1) or other measures of training load. Here, we assume there is no contribution from an artificial coach that might process training indexes autonomously and independently (e.g. average session HR).
At Level 1 in athletes/coaches, we might see examples where athletes or coaches begin trusting the data more than their gut feelings. Is this hard to believe? Perhaps this is where the debate surrounding the use of power meters in cycling is at currently (see e.g. Cycling Weekly). More often than not, cyclists may rely on numbers provided by their power meter and HR monitor and adjust the pace accordingly. The main difference between Level 0 and 1 is, in this case, reliance on the artificial system, over trust in personal feelings, knowledge, and intuition i.e.: the human factor.
From Level 2 to 4, there is a progressive overtaking of AI over human intelligence in the decision-making processes. This implies an increasing reliance on sensors, data and software that can automatically compute and prescribe training loads and recovery behaviour autonomously. At these levels, coaches design the training programs alongside their known context, but in accordance with the instructions provided by the machines, prior to delivery to the athlete.
Level 5: end of the relationship between athlete and human coach. The athlete must rely only on the machine coach for every decision. Here, it’s important to note that this level is prohibited by law in the case of autonomous driving, which is why I left a question mark in my example on coaching and sport in general. Sport is highly performance-driven, and if it can be proven that machine coaches are better than human coaches, then athletes and/or performance management will naturally shift to reap the rewards.
The intelligence of a machine coach
My interest in the modelling of the chronic adaptations to training dates back to 2013 when I first read the paper by Clarke and Skiba (4). I’m sure I’m not the only scientist that finds inspiration from their manuscript and their simple implementation of Banister’s dose-response model (1) in an Excel spreadsheet! Forty-five years following its first release, the Banister model is still implemented today, and counts an impressive 332 citations (source: Scholar). In a recent paper published in EJSS, Mitchell et al. (5) compared the performance of the Banister model with an artificially intelligent model (a neural network) in tracking and predicting performance in three elite swimmers. Not surprisingly, the neural network outperformed the other equation-based models in the tracking test, but performance was not maintained in the prediction phase. Correctly, the authors conclude that a model with more parameters is needed to better interpolate the data, but equally might perform worse in predicting the next performance point. Understandably, the authors call for other data sources (such as: propelling efficiency), different from performance and training data alone.
When developing an AI, we should consider that we might want to apply the same algorithm in different tasks. The ability to perform well in different tasks remains the holy grail of the implementation of artificial intelligence in sport science and coaching, as this is one of the most important traits of an intelligent system. On this note, in a recent pre-print paper (3), François Chollet (the father of Keras (2)) proposes a set of guidelines for defining intelligence. This new definition relies on concepts such as the prior knowledge, experience, generalisation difficulty and skill-acquisition efficiency. According to the author, this is only meant to compare different intelligences (e.g. human vs. artificial) and not to challenge only human intelligence. One of the pillars that constitute the structure of this new definition of intelligence is the “efficiency with which a learning system turns experience and priors into skill at previously unknown tasks”.
What does this mean for the machine coach that could progressively take over the human coach from a 0 to 5 level? Let’s assume that we were able to implement the perfect artificial intelligent Banister model. We would first need to confirm that this model is able to predict the performance of athletes across a number of different tasks. In this case, the term generalizability might indicate the ability of the coach to transfer the prior and acquired knowledge to other athletes. A greater ability to generalize might indicate that the coach is able to transfer the knowledge across different populations, e.g., from athletes to sedentary individuals. An even higher level might indicate the ability to predict adaptations to a hot environment, to different diets, to caffeine ingestion, and on and on and on!
It’s really hard for me to picture a future where machines will be able to collect their own notions of physiological adaptations, before connecting them and deploying their own ideas. It’s easier to imagine a future where humans will leverage the computational and storing ability of the machines, and where artificially intelligent systems will be used by humans to think wider and deeper. If you think deeply on the topic, we are already exploiting the ability that machines have to connect notions. We rely on the storage offered by machines to look for definitions, data and numbers (just consider the “collective intelligence” developed within the Wikipedia project). We use machines even to connect thoughts, to make decisions and, at the end of the day, we literally think together with them. With the shortening of the computational times, the growth of cloud computing and cloud storages, I believe that the ability to exploit this hybrid thinking will make the difference in the great majority of our applications.
Conclusion
The thought that I can understand the universe where I am now, how the human body reacts to different exercise stresses and why is absolutely wonderful. The fact that I can leverage human-made AI to go even deeper in my understanding, makes everything even more exciting. In the last decades, data scientists opened a door of wonder for us, and I have no sense whatsoever that they diminished anything. Our need to conceptualise and understand the world surrounding us, will not be diminished, nor demolished, by any AI. To me, this quest to seek the truth, a core endeavour of humanity for researchers and scientists, is still the greatest show on earth.
*Title of this blog post was inspired by the work of Richard Dawkins
REFERENCES
Figure 1. Process of testing, verification, validation and implementation of a new in-silico model.
Figure 2. Different levels of automation for a machine coach. Comparison with the different levels used in the automotive industry.
- Banister, E, Calvert, T, Savage, M, and Bach, T. A systems model of training for athletic performance. Aust J Sports Med 7: 57–61, 1975.
- Chollet, F. Keras., 2015.
- Chollet, F. On the Measure of Intelligence. arXiv:191101547 [cs] , 2019.Available from: http://arxiv.org/abs/1911.01547
- Clarke, DC and Skiba, PF. Rationale and resources for teaching the mathematical modeling of athletic training and performance. Advances in physiology education 37: 134–152, 2013.
- Mitchell, LJG, Rattray, B, Fowlie, J, Saunders, PU, and Pyne, DB. The impact of different training load quantification and modelling methodologies on performance predictions in elite swimmers. European Journal of Sport Science 1–10, 2020.
- Topol, EJ. High-performance medicine: the convergence of human and artificial intelligence. Nature Medicine 25: 44–56, 2019.
- Zignoli, A, Fornasiero, A, Bertolazzi, E, Pellegrini, B, Schena, F, Biral, F, et al. State-of-the art concepts and future directions in modelling oxygen consumption and lactate concentration in cycling exercise. Sport Sciences for Health 1–16, 2019.
- Zignoli, A, Fornasiero, A, Ragni, M, Pellegrini, B, Schena, F, Biral, F, et al. Estimating an individual’s oxygen uptake during cycling exercise with a recurrent neural network trained from easy-to-obtain inputs: a pilot study. PLoS ONE (in press), 2020.
- Zignoli, A, Fornasiero, A, Stella, F, Pellegrini, B, Schena, F, Biral, F, et al. Expert-level classification of ventilatory thresholds from cardiopulmonary exercising test data with recurrent neural networks. European journal of sport science 1–9, 2019.





